DevOpsDays Amsterdam 2016: Day One
Table of Contents
My notes from the first day of DevOpsDays Amsterdam 2016.
Opening welcome
DevOpsDays is hosted on every continent (except Antarctica), 35 events in 2016, 13 already completed.
The fourth edition of DevOpsDays Amsterdam. People from more than 20 countries. 150 persons attended the workshops.
Opening Keynote: It’s Not Easy — Erica Baker (Slack)
Besides being a build and release engineer at Slack, Erica is a diversity and inclusion advocate both within Slack and outside it.
The tech world is not a meritocracy! (Apparently the word was made up, as a joke, but we still use it though.) Personal biases lead to pattern matching for who is going to be successful.
Research on people working at major tech companies showed that those companies have hired from a few universities. Conclusion: if you want to have a better chance of a job in Silicon Valley, you should go to Berkeley or Stanford. However, you have to have the right background (right school, right activities) to get accepted. This way the system has been designed for people with a similar profile. In other words: by design we exclude people that would otherwise be successful.
There are not just issues with diversity, but also inclusion. Underrepresented people hear all kind of nasty stuff at work. As a result these people do not like going to work, or conferences for that matter.
If you build a product that is meant to be used by everybody in the world, you want to have everybody in the room. (It seems like Nikon did not have Asian people working on the team that created the S630 camera.)
There are many things that need to be addressed regarding diversity and inclusion. Erica needs our help: tell your company you need a more diverse team.
People are uncomfortable with the subject. Be willing to be uncomfortable. Recognise that others are also human beings. Approach people with understanding and be open.
Perhaps we should do a post-mortem on the tech industry to find out why we have diversity and inclusion issues. Erica doesn’t know a single company that has solved them all.
The Evolution of Automation — Adam Jacob (Chef)
Adam wrote Chef. About a year and a half ago he went on vacation in Mexico and started thinking about a problem he was seeing with customers: how can we go faster?
It all starts with people: miserable people generate miserable products. Happy people however create happy products and happy companies.
Culture and technology are both relevant. Culture is improving. Let’s focus on the technology here.
Big companies have control over the application: they knew from the beginning what they were going to build. The platform is the product. The infrastructure must be arranged properly.
For e.g. banking this is different. If we would remove IT from a bank and go back to ledgers, the bank would still be a bank. The same goes for stores, etc.
So modelling your infrastructure like the big companies is probably problematic.
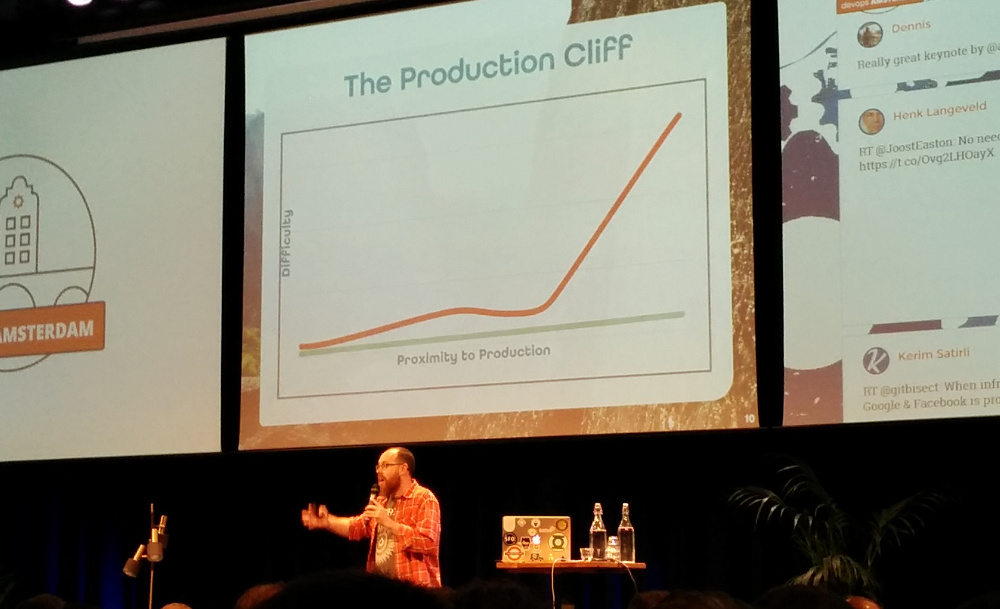
Adam talked about “The Production Cliff”: the closer you get to production, the more problems you’ll encounter.
Habitat
All of this lead to Adam creating Habitat: application automation. Manage the application, not the infrastructure.
The automation travels with the application. If we do this, it will be:
- Autonomous
- Idempotent
- Convergent
- Declarative
- Abstract
- Immutable
Ask the application to do e.g. runtime config, service discovery, secrets management. Then going to production is not such a big problem.
Features of Habitat: low abstraction, complete dependencies, declare services, simple functions. human centric, supports comments, supports complex data structures.
Software gets built in a studio. This is a cleanroom environment. One of the benefits is that you know all dependencies are present in the configuration.
Note that Habitat can export to, amongst others, Docker.
Habitat supervisor runs services and configures environments. Supervisors form a “ring” to share configuration and adapt to changing conditions.
(Adam gave a demo of Habitat at this point.)
By focusing on how it would feel to go into production, it changed how we thought about how to build the automation.
How the hell do I run my microservices in production, and will it scale? — Daniël van Gils (Cloud66)
How are customers of Cloud66 running Docker in production?
From starting out with Docker to going into production, there is a lot of noise. Due to Docker being only three years old, we are still figuring out stuff. This also generates a lot of noise.
The right container image
You need to think about the process where you take your code and create Docker images. The right image should be the same in all your environments.
Most of the Cloud66 customers usually start by creating the image as a VM.
The right container needs to be:
- Slim
- smallest minimal image, remove compile time dependencies, remove packages, squash layers, run stats for the image, habitus.io.
- Secure
- remove secrets, patch security updates, run the application inside the container with right UID, test the image (Docker Bench for Security)
- Speedy
- optimise code, memory & CPU usage, one process, load testing
- Stable
- lock image versions (
latesttag can change), lock runtime versions, tag your image, proper logging (what image is running in production) - Set
- use volumes wisely (use external services instead of abusing the host system), loosely coupled, remove things that are hard to maintain in production (like running database in a container)
Containers in production
Some stats:
- About 70% of the Cloud66 customers have monolith, multi tenant containers.
- Around 20% API first containerisation.
- Finally, circa 6% are working on splitting the monolith.
- The remainder, about 4%, a microservice architecture.
We talked about microservices and a microimages, but is the platform also micro?
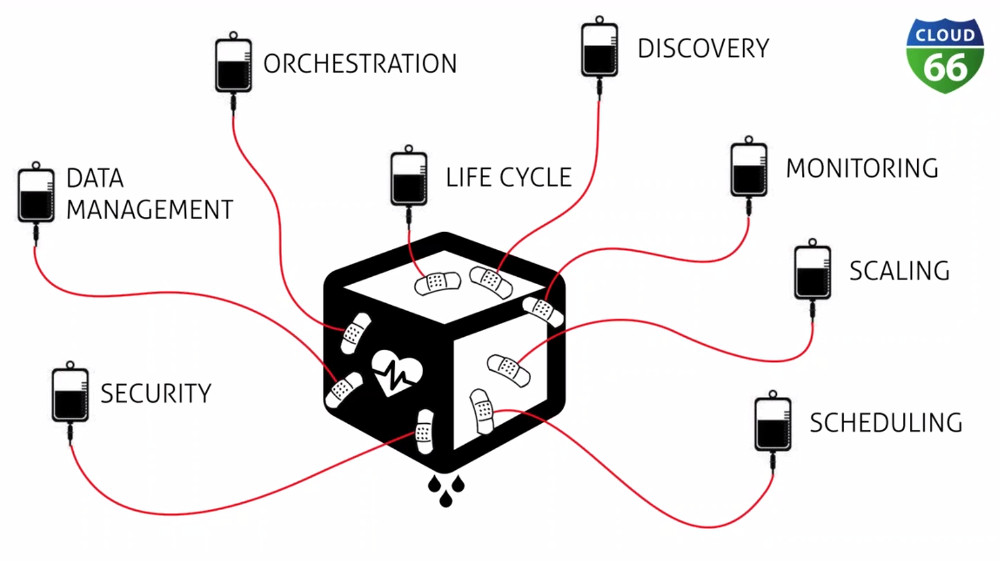
Taken from the “How to Build, Test & Deploy Docker Images when Running Microservices in Production” webinar since I failed to make a readable photo during Daniëls presentation on DevOpsDays
With all of the attached concepts, like security, monitoring, scheduling, etc, you have an elephant as a platform to run your microservices. Pick your platform wisely.
- Question: How do you manage stateful services (e.g. a database)?
- Opinionated answer: hard to run them in a container, deploy them like you do normally (VM, bare metal). Easier with backups.
- Question: How do you monitor thousand services?
- Answer: ELK Stack, telegraph to collect metrics, put in time based database. Make sure you have log conventions Can result in big database.
DevOps has Always Been About Security — Warner Moore (CoverMyMeds)
This is a talk about innovating with technology and still be secure. And how to talk to people about compliancy.
Restricting access comes at a cost. Its going to slow down the use of the technology.
When developers do not have access to the production environment and can only change the system via commits, you automatically have an audit log. This is going to make an auditor happy.
If you are already doing peer reviews, you may not need a separate approval process. Note that this peer review can also include a security review. This way you embed security in the development process.
A combination of monitoring and centralised logging, e.g. using the ELK Stack or Splunk (if you want to buy things), can increase the security level.
What we are doing with automation makes us more secure.
Don’t forget to include the information security people. We can educate them so they can support us.
Databases are where we usually compromise. BI tools can solve that problem. Databases can be automated too. And adding test data to the code makes it easier to develop.
Compliance (PCI, HIPAA, privacy laws): the controls we build in our automation tools will check a lot (all?) of the boxes.
Physical and logical separation can be solutions to get stuff out of scope for compliancy audits.
The Mathematics of Reliability — Avishai Ish-Shalom (Fewbytes)
The goal of this talk: get people to think analytically.
You cannot bolt on reliability later (just as with security).
Mathematics is about modelling, proving your assumptions. A lot of things that seem obvious, actually are not.
How to define reliability? First you need to define what failure is. An engineer would say something like “Failure is when a system is operating outside of the specified parameters.” In practice: a system is failing when users are complaining. This also means that failure is subjective. (An example: if a web page takes 1 second to load, is that a failure?)
Possible states of a system: working OK, failure, unknown, fuzzy. The “unknown” state is often forgotten, but very important. Fuzzy means that it’s not clear when a system is working correctly.
Mean time between failure (MTBF) is only relevant when talking about a large number. It is not applicable when you are only talking about a few systems over a limited amount of time. Statistical predictions about a single system are not useful.
A lot of fallacies around statistical independence: the hot hand fallacy, the gambler’s fallacy.
Serial reliability: the total reliability is a product (multiplication) of the reliability of all of its components. As a result the reliability of a complete system is always lower than that of the component with the lowest reliability. (For instance, a system with three components with, respectively, a reliability of 0.995, 0.99 and 0.95, has a total reliability of just 0.936.)
To improve this kind of system, you’ll get the biggest improvement by making the least reliable component more reliable.
Parallel reliability has to do with redundancy. Not enough redundancy will reduce your reliability. The “n+1” rule (where you have one spare) is only true for small clusters.
Statistically dependent/correlated failures:
- shared workload
- shared code
- shared infrastructure
Backup and operational sub-system should avoid coupling with primaries. For instance, if you monitoring shares a component with the production environment, then your monitoring could go down when you need it most: when production goes down.
An example of base rate fallacy: if you have an active/standby failover where a failed master is always detected, and there is a 2% probability of false positive (master working, detected as failed), there is a probability of about 95% that failover is erroneous. And failovers can cause severe issues.
To solve this, you can disable automatic failover (as GitHub did after earlier problems), greatly reduce false positives or use an active/active setup.
Microservices have a lot of dependencies. Use circuit breakers to increase reliability.
Queuing delay: when a certain limit is reached the system will start falling over. Throttle your queuing to prevent this. When a queue starts to build up inside the system, you can apply back push to the system adding the items to the queue.
Little’s law: relation between throughput, capacity and latency. (Obvious law, mathematically hard to prove.) One failed server in a cluster of three can cause a high failure rate if that one failed server was taking more load than it should (because it was e.g. faster). Throttle to balance the load better.
Summary: reliability is everyone’s responsibility.
Ignites
Ignites are five minute talks with twenty auto-advancing slides in which you can share anything you want: tips, tools, war stories, etc.
Breaking Brooks’s Law with DevOps — Jason Yee (Datadog)
Brooks’s Law dispelled the myth that if you throw more engineers on a problem, it will be solved quicker. The reasons:
- Getting the new engineers ramped up costs time.
- The divisibility of work is limited.
- Communication overhead.
It’s even worse: after a certain inflection point, adding more people the team slows down due to the increased communication.
Stopping to communicate is not the answer though. You should communicate as much as possible and via as many ways as possible.
DevOps is about empowering people by building a culture of communication to inform and encourage decision making.
Break Brooks’s Law with a DevOps culture.
Jason published the sheets of this talk.
The importance of ‘why’ for software operations — Pavel Chunyayev (Levi9)
“Why?” is an important question, it’s answer is the purpose of the company. Before asking “what?” or “how?” first ask “why?”
Do not tell your employees what they should do or how they should to it. Situations can change; tomorrow will be different than today. But when the why—the vision—is known, people can improvise. They will not be able to do that (as effectively) if they were only told the what or how.
So start with the why, then the what and how.
You Don’t Belong Here: Dealing with Imposter Syndrome — Jody Wolfborn (Chef)
Imposter syndrome: anxiety that you don’t belong here and you’ll be exposed.
An estimated 70% of of people affected by imposter syndrome and not just in tech.
Some tips that might help you to overcome it:
- the bumps in the road help you grow, take those and go forward
- build an inner circle to support you, but pick carefully: you need them also to tell you what you can improve on
- know what triggers your imposter syndrome
- listen to your body: if you feel unhealthy it is easier to get depressed
Be aware that someone else might also suffer from it, so be careful with what you say. What triggers imposter syndrome for you, might also trigger it for others.
You are not alone!
You might not be perfect, but you can be good!
Document Writing in CI Environment — Takahiko Ito
Software engineers write many documents (manuals, technical books, etc). To assist them, Takahiko created RedPen.
RedPen is a documentation checker. It can check, for instance, the aforementioned documents, but also commit messages.
The software can detect problems in the input, like long sentences, sentences starting with a lower case letter and incorrect spelling. The user can configure which checks should be performed.
It has integration for a bunch of editors and can parse (amongst others) Markdown, AsciiDoc and LaTeX.
RedPen can become a part of your CI, e.g by using TravisCI.
For more information see https://redpen.cc/.