DevOpsDays Amsterdam 2017: day one
Table of Contents
These are the notes I took on the first conference day of DevOpsDays Amsterdam 2017.
Opening Welcome: 7.5 years of #devopsdays, 5 years in Amsterdam — Kris Buytaert (Inuits)
Kris walks us through the beginning of DevOpsDays.
The idea for DevOpsDays started in 2007 in the Antwerp Zoo. Imagine a Venn diagram with three circles: open source, agile and “cloudy stuff.” DevOps is where the tree circles overlap.
The first conference was in 2009 in Gent. Initially there were two conferences per year: one in Europe, one in the USA but this grew steadily. The first conference in Amsterdam was in 2013. There have been 175 events so far.
Kris noticed some trends: animals, names (lots of speakers named Mark/Marc, Michael and Jeffrey) and hidden contests (worst t-shirt, beers).

Although the open space topics have become predictable, there is an evolution in topics like culture, automation, monitoring.
Important takeaway: tools will not fix your broken culture. The tooling hype is not helping. Stop looking at the hype and start thinking about what matters: how can we help the business go forward?
Video on of this talk on YouTube
Keynote: Building Bridges with Effective DevOps — Ryn Daniels (former: Etsy, future: Travis CI)
According to research, after 10 years in the industry (‘mid career’), 56% of the women left have the industry.
There are six causes for burnout identified by Dr. Christina Maslach: disconnection of workload, control, rewards, fairness, values or community. Ryn adds “disconnection of the industry itself” to that list. Some possible causes: being the only women in ops, being the only ops engineer in a company. In general: feeling like being “the only one.”
Breaking down silos is not only good for companies but also for people.

Four pillars of effective DevOps:
- Collaboration: individual people working together with shared interactions.
- Affinity: building inter-team relationships, empathy and trust.
- Tools: accelerators of culture.
- Scaling: applying the considerations of collaboration, affinity and tooling throughout the various inflection points of an organisation’s life cycle.
The four pillars all help with creating connections. But here comes the same quote again:
Tools will not fix a broken culture.
A couple of the things that worked for Etsy to create connections:
- Bootcamps: new hires work on other (related) teams than where they will eventually work on for the first weeks of employment. This builds relationships, understanding and empathy.
- Yearly rotations: work on other engineering teams for a month once a year. (This was the most effective to build relationships.)
- Inter-team relationships:
- Dedicated: dedicated to work 100% on team/project.
- Designated: designated point of contact (with other responsibilities).
- Embedded: working as full member of given team (e.g. an ops engineer embedded in another team).
- Transparent culture.
We do not want to separate the engineers from the non-engineers. We want to have connections throughout the entire organisation. Ideas to connect the entire business (and not just developers and operations people):
- Support rotations (engineers spend time working on customer support)
- Shared tools and processes
- Focus on the customers
Create connections by working on an inclusive industry. We do not want people to feel excluded and get out of the industry because of it.
Empathy allows people to help each other create the most inclusive industry on behalf of everyone working in it.
We can use differences to enhance creativity. But how do different opinions actually get treated?
Technology is a means to an end. Solving problems for people is the end goal.
DevOps uses empathy to create and enhance connections between us.
Call to action:
- Be inclusive
- Break down silos
- Build bridges
Resources:
- Slides (PDF)
- Video on of this talk on YouTube
- The book Ryn co-wrote: Effective DevOps
- Empathy: The Essence of DevOps
Start-up Culture at Scale — Matthew Slane (Skyscanner)
This talk is about how Skyscanner attempts to create a start-up culture with lots and lots of engineers.
Skyscanner is a Scottish company with more than 800 employees and over 50 nationalities.

Previously they were on a 6 week release cycle. Feature squads worked on a feature and then moved on to the next feature, basically leaving the newly written code to rot.
Skyscanner first had to stop to be able to go faster: fix bugs, get a stable product. They started using the theory of constraints (introduced by Eliyahu Goldratt in the book The Goal) as a tool to get to the best flow.
Skyscanner changed the organisation to the Spotify model which means the engineers are organised in squads: small teams that own a small number of products. Squads are loosely coupled.
The right balance between business alignment and autonomy needed is needed. Both the squad members and the business have to be happy. Squads have autonomy, but they also have the responsibility to align with the business. This requires trust.
It takes time to get it right:
- Initially too much autonomy which lead to local optimisations (e.g. too many programming languages in use).
- Squads with too many responsibilities.
- Squads placed in the wrong tribes.
- The tribe structure must be right (which is hard!).
- Review the situation regularly.
- Be flexible (e.g. pop-up squads, disband/create squads when necessary).
What has changed for Skyscanner:
- Collaboration has improved.
- Vision of business is still hard.
- Not just engineering, but the whole company works in squads and uses agile methodologies.
- Communication is hard, which is normal for a big organisation but the structure Skyscanner is using makes it even harder.
Resources:
DevSecOps: Security at DevOps Speed — Ilkka Turunen (Sonatype)
Ilkka figures out software supply chain problems. How to deal with open source artefacts? He is a software developer, not security guy. He has been giving these kind of talks for a while now, and this feels like the first year that the industry is taking notice of DevSecOps.
Software is moving into parts of our lives that it has not been before. At the same time: developers outnumber application security people in a 100 to 1 ratio.
Most effect is had in building defensible infrastructure. Where would you rather be during a zombie apocalypse? A castle or a shed which has security measures bolted on?

However, in our industry we are on the opposite side. We spend quite a bit on countermeasures instead of going back to the basics and building a safe infrastructure.
About 80 to 90% of typical applications is composed of components like Docker, npm, etc. An average application consists of 106 components (based on a survey of 25000 applications).
Of the 1300 companies that were interviewed, 1 in 5 had or suspected a breach related to an open source component. Developers spend little time in determining if a component they (want to) use is actually secure.
Security needs to be a part of everyday application development and delivery. Find tools that fit early on in the pipeline and give developers feedback as soon as possible.
Other tips:
- Design an approach that works with, not against the developers.
- Know what you run (applications, OS packages, libraries) and where you run it.
Resources:
- Slides (PDF)
- Video on of this talk on YouTube
- The Sonatype 2017 DevSecOps Community Survey
- The GitHub repo Awesome DevSecOps
Resilient Systems Require Resilient People — Hannah Foxwell (Server Density)
We are not like our platforms: we are not immutable or highly available and we are ephemeral. This talk is about people.
Resilience is the ability to recover quickly from difficulties. We rarely talk about resilience of people, only about our infrastructure (load balancers, etc.). You cannot upgrade a person overnight. Change takes time and often it will take a toll on the individual.
This isn’t a talk about “what is wrong with you” but how we can help ourselves and others to become more resilient.
On the first day of her first job, Hannah and other new hires were told about the “well of despair” and that it is a normal phenomenon. This made it possible for them to talk about it with others.
When you are just out of the well of despair because of change X, then next change is already going on and you might end up in the well again. The rate of change of technology outpaces the human ability to adapt. This does not help.
However, resilience can be improved—it is not a trait you have or not. It’s a set of skills you can improve and enhance.
The locus of control is the degree to which you believe you have influence on the outcome of a situation by hard work and decisions. Increasing this, increases resilience.
Things like trust, autonomy, loosely coupled services and continuous delivery pipelines can improve this internal locus of control.

Tips to improve resilience:
- Offer caring, listening and supporting relationships.
- For teams:
- Support each other.
- Trust people and give autonomy.
- Provide sense of purpose.
- Focus on opportunity (re-frame the problems you face).
- Provide constructive feedback (how to get better next time).
- Develop coaching skills.
- Be optimistic and confident in the face of setbacks.
- Build a community (ideally within the company, alternatively e.g. the DevOps community).
How to improve your own resilience:
- Take breaks to reduce stress levels.
- Observe your own thoughts, don’t become your thoughts (don’t panic, disassociate yourself from your feelings).
- Look after your health.
- Talk about it!
- Reduce input (you don’t have to be “on” every moment of the day).
- Meditate.
If it doesn’t challenge you, it won’t change you.
Adopt learning behaviours, build on your resilience. Include aspects like how we feel about our work into your retrospectives.
Resources:
Terminal Velocity: Doing DevOps Right by Removing CLIs from Production Environments — Matthew Simons (Workiva)
This talk is not just about CLIs, but all things that let you break stuff easily. It’s also not just about production environments, but all places where breaking things is really bad (e.g. your Docker registry).
Case studies:
- The recent Amazon S3 outage
- Azure, during deployment
- GitLab earlier this year
- Level 3
Commonalities: things going wrong during crisis because of running ‘arbitrary’ code in production.

We (humans) are the single point of failure. People don’t scale. Manual processes don’t scale.
Ops lock-in: When your organization cannot innovate faster than your ops team will allow or willing to support.
Code is safe(r). By moving to operations as code or crisis response as code, things that impact production are safe.
Common components:
- Source control
- Review
- Testing
- Sanity checking at runtime
Example:
- Code is pushed to GitHub.
- Via webhooks a compliance bot is triggered (checks repo conventions, check the number of reviews, etc)
- Code is sent through a dry run (testing, sanity checking)
Based on the output, we can put the change in production. Or not.
Summary:
- Remove things that let you break stuff easily from places where breaking things is bad.
- Operations as code, crisis response as code, everything as code.
- Don’t be a single point of failure.
- Do it for you!
Resources:
Ignites
The concept of ignites: the speaker provides twenty slides and a new slide is shown automatically every 15 seconds.
Integrating security into your devops: use a security automation pipeline — Jeroen Willemsen (Xebia)
Besides a build pipeline (which includes unit tests, a build step, storing artefacts, deployment, etc.) we also need security pipelines.
A security pipeline can:
- Check licenses and dependencies.
- Do runtime analysis.
- Perform scans.
Tools you can consider:
- Zed Attack Proxy (ZAP), a penetration testing tool for web applications.
- Clair, a static analysis of vulnerabilities in application containers.
- DefectDojo, to track testing efforts.
Think big, start small. But most of all, start
DevOps is Gezellig — Jason Yee (Datadog)
Jason explained Dutch words (lekker, leuk, gezellig, stamppot) and concepts to non-Dutch attendees.
DevOps is like stamppot: you take what you’ve got, mash it together and go with it. However, DevOps is an iterative process: you can replace the parts that don’t work with other parts.
Devs on-call? Yes, it is possible! Implementing the new thinking of “on-call!” — Aaron Atwell (VictorOps)
For developers it’s scary to be on-call. However: people just want to be able to reach you, just in case. You don’t have to know everything. You only have to be helpful and be there.
Tips:
- Learn alert triggers (what do they mean?)
- Participate in post-incident analysis
How to make good and difficult decisions — Bernd Erk (Netways)
On average we make 35000 decisions a day. To get an idea: food is good for over 200 decisions per day. There are easy and hard decisions. Hard choices are hard because there is no ‘best’ option.
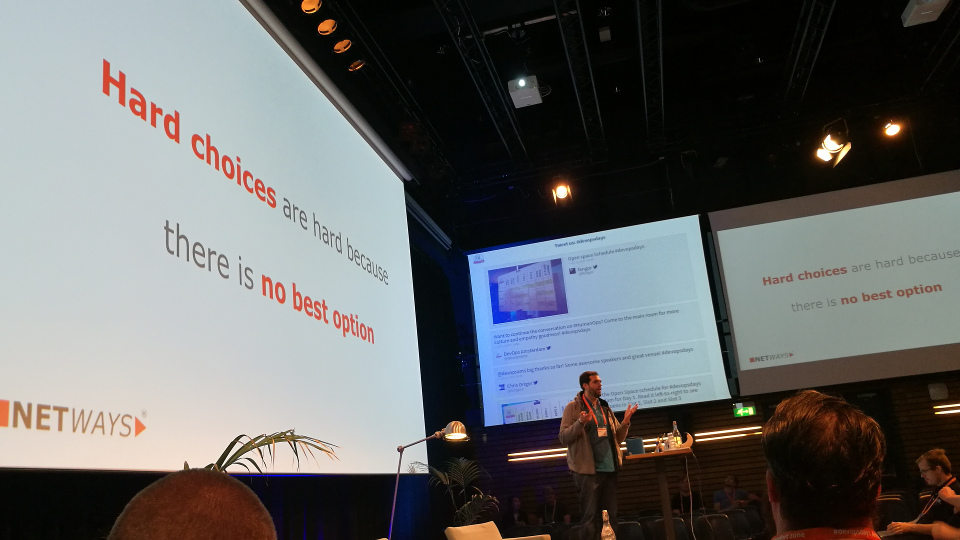
Tips to make good choices:
- Avoid stress (under stress the fight-or-flight mode is activated)
- Try to avoid perfection (in hard choices there probably is no perfect solution)
There are several forms of biases. Possible solutions to overcome these:
- Self-serving bias:
- Create a good culture of failure.
- Try to make friends that can warn you.
- Confirmation bias:
- Search for the opposite of what you are leaning towards.
- Cognitive fluency:
- If it sounds too good, be careful.
- Sunk cost bias:
- Focus on future investments.
- Evaluate the current situation as if it was just another option.
- Create a culture of failure.
Hard decisions are chances to decide what we want to be.
Tip to avoid group thinking when making decisions in a group: each person writes his/her idea down and have a discussion afterwards.
Resources:
- Slides: SlideShare and PDF
How to do HumanOps — David Mytton (Server Density)
Server Density started a “HumanOps” community last year. HumanOps is the idea to think about the human side of your organisation.

Twelve principles:
- Humans build and fix systems.
- Humans get tired and stressed, they feel happy and sad.
- Systems don’t have feelings (yet), only SLAs.
- Humans need to switch off and on again.
- Well-being of human operators impacts the well-being of systems.
- Alert fatigue == Human fatigue.
- Automate. Escalate to a human as a last resort.
- Document everything. Train everyone.
- Kill the shame game.
- Human issues are system issues.
- Human health impacts business health.
- Humans > systems.
More information on humanops.com
Resources:
Operations in Jip-en-Janneke taal — Jonathan Lukkien (bol.com)
Jonathan, as a new(ish) developer at bol.com, had to respond to problems in the system. This resulted in him asking a lot of ‘dumb’ questions. He would have liked to have a runbook to know what to do when there were problems.
Two years ago, bol.com went from having big releases every month to smaller chunks going into production. Now all teams can deploy what and when they want (obviously after testing them).
They have the philosophy “you build it, you run it, you love it (and take care of it).” This requires a lot of knowledge of the systems your services are running on/with.
Bothering SRT teams (their operations people) and asking stupid questions does not scale. Jonathan wanted to share knowledge.

They created a guide to diagnose the problem. It had items like:
- Acknowledge the problem (to prevent further pages to other teams)
- Where?
- …
- How to mitigate?
- Post mortem
This was just a start. They started writing runbooks—in their own language—and had them validated by the SRT teams. The fact that they are written in their own language, removes a barrier for people who would otherwise be intimidated by jargon or technical details.
A tip for ops to help with sharing knowledge with developers: document new things not just from one silo, but share from the get-go. Involve dev teams from the start.