Devopsdays Amsterdam 2018: day one
Table of Contents
After the workshops from yesterday, this was the first day filled with talks.
Note: these are my notes. They are not necessarily representative summaries of the talks.
Welcome to devopsdays Amsterdam 6 — Peter Nijenhuis
Continuous improvement is part of DevOps. We improve things we want to be better, like our build pipeline. Don’t forget to also improving yourself!
Cloud, containers, Kubernetes — Bridget Kromhout (Microsoft)
The title was a way to get all the buzzwords on one slide. And they are hand-wavy enough to be able to talk about anything. ;-)

Rollbacks are a damn, dirty lie.
We can only move forward to a future state which we hope is similar to the old state.
Containers solve problems in our deployments. They make it a lot easier to ship for example. They do not magically solve all the problems you have. You get new problems, like having to update your base images.
We have had container like things in the past: chroot, FreeBSD jails, Solaris Zones and LXC. Containers have become mainstream now and are easier to use. It is exciting to talk about orchestration, service meshes and storage today. However, orchestration and such are a means to an end, they are not the goal itself.
It is hard and a lot of work to take care of your application and the layers beneath it, all the way down to the hardware. Especially given that disruption is part if daily life—you know that stuff is going to happen.
Our systems could be less complex, but there is also a lot of “résumé-driven development.” We should not add things “because.” It is very tempting to build whatever is exciting. For instance: microservices makes some things more complex, so you have to know what problems they are solving in your case and then decide if it is worth the added complexity.
If you want to use Kubernetes, be aware it also adds complexity. To learn about it, check out:
- https://github.com/kelseyhightower/kubernetes-the-hard-way
- https://github.com/ivanfioravanti/kubernetes-the-hard-way-on-azure
- https://github.com/jpetazzo/container.training
Picking the “right” things to use is a hard problem. Check out the Cloud Native Computing Foundation website and see how many projects there are! Kubernetes is the only “graduated” project, all the other projects move even faster than Kubernetes.
“Legacy” is where the customers and money live. We are not operating in a vacuum. We are working in a wider ecosystem which still matters and should be taken into consideration.
Projects to watch:
- Helm (package manager for Kubernetes)
- Brigade (when you get sick of the YAML or find it not flexible enough)
- Virtual Kubelet (add legacy systems to your clusters)
Bridget reiterates that Kubernetes is a tool, not the end game.
In a world that celebrates pioneers—be the settlers instead.
We can end up feeling negative. DevOps should not be sadness as a
service.
We should stay positive.
We, the nerds have won and we probably should not screw this up. We have the opportunity to shape reality. Which is a profound responsibility. We should make the world we are living in a world we want to live in.
Ask yourself the question “how can I enable someone in another team to spend their time better?”
The rocky path to migrating production applications to serverless architecture — Serhat Can (OpsGenie)
Examples of when serverless is not great.
They do not hate serverless/AWS Lambda at OpsGenie, but they have had their problems.
The serverless journey of OpsGenie began in 2015 with small scale custom integration. In 2017 they started to use AWS Lambda for a production service. In 2018 they started a spin-off, Thundra, to offer observability for AWS Lambda.
OpsGenie stack:
- Java 8
- AWS services, including “serverless” DynamoDB, SQS
Some of the problems they had (and their solutions):
- Cold start
- Increase memory (and pay more).
- Lightweight application framework (instead of using e.g. Sprint).
- Do some ‘smart’ warmup.
- Scaling
- Don’t put your functions in a VPC unless you have to.
- Use you 6th sense to debug a scaling issue.
- Observability
- AWS X-Ray can help, but is often not enough.
- Custom tooling, Thundra spin-off.
- Event driven (unexpected bills from AWS)
- Avoid infinite retries.
- Monitor and alert for pricing (unfortunately no specific pricing metric for AWS Lambda).
- Think of Cloudwatch costs and sample logs & metrics.
- Idempotency
- Design the function idempotent, taking the type into consideration.

DevOps and Cloud Native — Michael Ducy (Sysdig)
Mapping existing principles into a DevOps world.
Definition of DevOps: CALMS
- Culture
- People over process.
- Failure is normal and is something you can learn from.
- Treat everyone as a valuable member of the team we can learn from.
- Automation
- You need a level of automation to get to x deploys per day.
- Use Infrastructure as Code, Continuous Integration, Continuous Deployment.
- Lean
- Learning from other industries about their manufacturing and production processes.
- Removing waste from processes.
- Measurement
- Performance, process and people metrics.
- DORA: DevOps Research Assessment (authors of The State of DevOps Report)
- Sharing
- Intra- and inter organization.
- Best practices and learnings to improve overall industry.
- Share work and code.
What is Cloud Native? Basically an architectural pattern. Joe Beda’s definition includes “teams” and “culture”:
Cloud Native is structuring teams, culture and technology to utilize automation and architectures to manage complexity and unlock velocity.
Pivotal has a nice image to explain Cloud Native:

Cloud Native in CALMS terms:
- Culture: blameless, inclusion & diversity, self-care and fail fast.
- Automation, Lean, Measurement: Cloud Native, we’ll get to this in a moment.
- Sharing: open source, public postmortems, public presentations.
When we zoom in on the automation, measurement and lean components:
- Automation
- Automation is a first principle of Cloud Native, built into the platform. The platform has scaling built in. You don’t have to worry about the platform, only your own application.
- Makes Infrastructure as Code easier (GitOps for example).
- Orchestration is incorporated from the start via Kubernetes which provides abstractions and robustness.
- Service Mesh as proxy for service requests, discovery, etc and to detect abnormal conditions.
- Measurement
- Common instrumentation, like Prometheus. Instrumentation means visibility.
- Distributed tracing is a new, but interesting development to correlate events through the distributed stack. Examples: Jaeger, Zipkin, etc.
- Service Mesh
- Lean:
- This is a side effect of Cloud Native because processes are improved, points of friction are removed and best practices are automated into the platform.
“DevOps team” is often a misnomer. What does this team do for the culture, lean, measurement and sharing aspects? Perhaps you mean the “automation team” instead? The DevOps team is often a developer services team, providing infrastructure, tooling and services.
What about Site Reliability Engineering? The Wikipedia article on SRE maps SRE on DevOps principles.
Summary:
- DevOps is the entire organization’s job, not one team.
- Cloud Native is a culmination of technological advancements.
- Cloud Native provides real benefits of agility and velocity.
Advice: watch the video 10+ Deploys Per Day: Dev and Ops Cooperation at Flickr again if you haven’t in a while.
Service mesh for microservices — Armon Dadgar (HashiCorp)
We used to have monoliths where multiple pieces of functionality were combined. Interaction between these components was quite easy; just a function call. We did use external components though, e.g. a load balancer and a database.
We stopped developing monoliths and started with microservices. The advantage is that we can release components independent from each other. We gained development agility. We lost on the operational side though. With microservices there are operational challenges, like discovery. Adding to this pain is a movement towards containers and a cloud environment, which means a much more dynamic environment.
Having multiple instances of a certain component means that you would probably place a load balancer in front of that component to distribute the requests. But now your load balancer has become the single point of failure. A central registry keeping track of what is running where (like Consul, ZooKeeper, etc) can help you out.
To mitigate attacks we need service segmentation. With the monolith we had three segments: the load balancer in front of the application, the monolith and the database. We used to have firewalls, virtual LANs, etc. Conceptually we are limiting the blast radius of an incident. But when you are using microservices, the story is not that simple anymore. There are still many components in a single segment. Segmentation with microservices is much harder since all components need to communicate. How do we segment these?
Infrastructure is a means to an end. Microservice architecture comes with a common set of challenges. Consul wants to provide common wheels for these challenges:
- Service discovery
- Via DNS (e.g “
dig redis.service.consul") or HTTP API. - You can hard code a name, not an IP.
- Via DNS (e.g “
- Service configuration
- Hierarchical key/value store with an HTTP API.
- Use Consul as distributed lock service.
- Service segmentation
- We’ll talk about this shortly.
Consul launched in 2014 and is the oldest application from HashiCorp and the application with the biggest footprint. Consul Connect was announced earlier this week and is meant to handle the service segmentation aspect:
- Service access graph: who can do what, based on service name not IP address (and thus scales better).
- Certificate authority, based on standard TLS. (The format is an X.509 certificate which is SPIFFE compatible.)
- Application integration:
- Sidecar proxy integration where the application connects to other components via the proxy (over an encrypted channel). No code changes needed. The proxy is pluggable: you can use other proxies like Envoy.
- Native integration. You do need to change your application, but lose the performance overhead of talking to the application. So if latency is an issue, have a look at native integration; otherwise use the proxy to keep flexibility.
Consul as a control plane, pluggable proxies as data plane.
Already using Consul and want to start with Consul Connect? Upgrade to the latest version of Consul (1.2.0 at the moment) and change three lines of code on the server and the client and you are good to go.
Don’t be a bystander, be an incident commander! — Rachael Byrne (PagerDuty)
Incident commanders are the key decision makers in the response to a major incident (and can even outrank the CEO during incidents, assuming you have leadership buy-in). Technical leaders seem to be the most likely incident commanders, but this does not scale very well since there are only that many of them.
Having non-technical incident commanders scales better. An incident commander does not have to know the tech stack. It does help to have a basic, high level understanding of system architecture.
Incident commander skills:
- Mind for process
- Communication (directive communication specifically, avoid too long discussions)
- Time boxing (time management, give people time boxes and check up on them, keep information flowing)
- Active listening

Once you have identified incident commanders, you need inclusive incident response training. Being outside of engineering is quite a hurdle to overcome for the incident commander, especially during a business critical time.
Advice for training:
- Define the role: responsible for communication and coordination. Incident commanders do not solve the problem themselves, they delegate to subject matter experts. (So that these experts can focus on solving the issue and not communication.)
- Make sure that the entire business understands the process of what happens during an outage.
- The trainee should shadow the experienced incident commander and silently observe (don’t interfere with the process, ask questions later).
- Scribe: the trainee keeps track of what happens. This helps with getting familiar with the process, plus it gives the feeling that you can contribute.
- Let the trainee handle a failure exercise.
- Reverse the shadow: the trainee becomes the commander. Note that the mentor should only provide help in the background to not undermine the trainee—the trainee is in command.
Celebrate that the trainee is now an incident commander!
DevOps is about creating empathy. Why stop at Dev and Ops and not include the whole business?
More information at https://response.pagerduty.com.
Ignites
Ignites are short talks. Each speaker provides twenty slides which automatically advance every fifteen seconds.
Going Dutch: observaties over Nederlandse cultuur & DevOps — Jason Yee (Datadog)
If you’ve walked around in Amsterdam you may have noticed that there are no curtains. Dutch people like their privacy, we just don’t want to block the view.
Since you write the software, you can remove the curtains from your application so you can look inside. The reason we are not doing this is because of silos: Dev does not talk to Ops and neither talks to the business people.
FEBO (known for its automat vending machines) reminds him of PaaS: fast and convenient. Dev can deploy and Ops need not be involved; everything will be fine, right?
Don’t be the FEBOps!
Better service leads to better food. Ops should be a service.
Go Dutch: share responsibility.
In summary: get visibility, focus on services and share responsibility.
Extreme feedback in DevOps — Joep Weijers (TOPdesk)
Email alerts from Jenkins have been abolished at TOPdesk. They needed something more “in your face.”
They use a build monitor for Jenkins and added a blue light which starts flashing when the build is broken. Not as easy to ignore as an email.
Using the @internetofshit twitter account as inspiration he came up with the following ideas:
- Automatically shooting developers that broke the build with a Nerf gun.
- A drone hoovering next to the developer that broke the build.
- Using the “The Car Hacker’s Handbook”: if you break the build, your car flashes its emergency lights. Or lock the car until the build is working again.
- Use the salary payment API to withhold the salary payment if the build breaks.
Talk selection as mockumentary film editing — Matty Stratton (PagerDuty)
Matty was responsible for a devopsdays talk selection. There were 176 talk submissions for only 18 slots last year.
A mockumentary is a fake documentary, heavily improvised (3–4 page script).
You don’t know what story you are going to tell when you start with a documentary. The same goes for organizing a conference. You are dependent on the submissions. You have to read all of them and a theme and story will come out. Start with an idea but be flexible.
Security as code — Geert van der Cruijsen (Xpirit) and Rene van Osnabrugge (Xpirit)
Rene and Geert both had an assignment: “implement a secure pipeline.”
The security officers they had to work with had a huge lists of compliancy rules. These rules are impossible to understand, implement, validate and maintain.
What usually happens is that once companies are compliant, the security level decreases over time until a next audit is near.
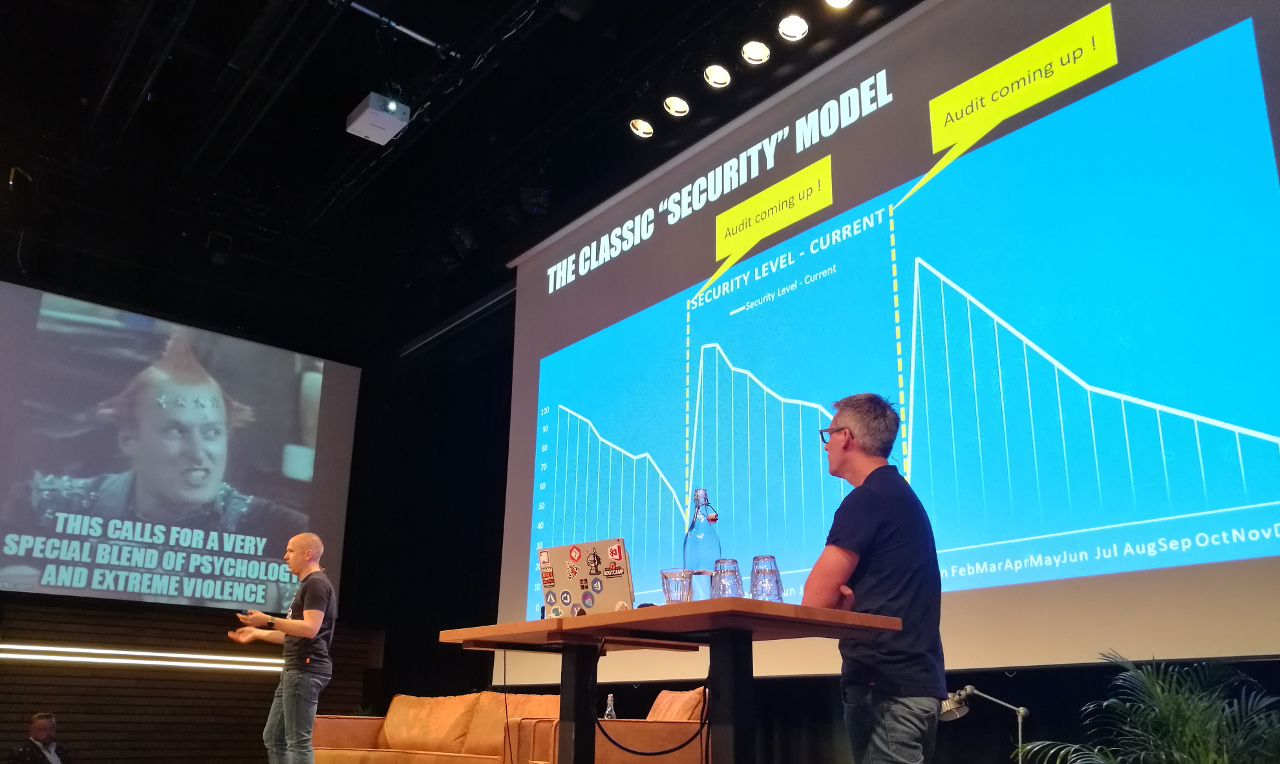
They needed a different solution. They got back to the “why” of the rules:
- Confidentiality
- Integrity
- Availability
Compliancy is not about security. If you are secure however, you are probably also compliant.
The way we do security checking now is not sustainable if we release more than a couple of times per year. Security is the next silo that should fall.
What needs to be secure?
- Infrastructure (servers & containers, firewalls & networks, identity & access)
- Applications (libraries, safe coding, passwords)
- Build and delivery pipeline
We need to move from a manual approach to an automated approach.
Phases:
- Identify the risks
- Work together with security (e.g. as part of the scrum team, even if only part-time).
- These days most applications consist for 80–90 percent out of third party code (libraries, containers, etc).
- Prevent bad things from happening
- Have a look at Gauntlet to check existing code and infrastructure.
- Scan for credentials.
- React if bad things happen
- Detect
- Monitor
- Have baselines
- Alerts
- Respond
- Mean time to recovery
- Pipelines
- Continuous delivery
- You build it, you run it
- Recover
- Post mortems
- Share experience
- Rebuild
- Everything as code
- Detect
Azure has the Secure DevOps Kit. You can use these tools to perform checks and generate reports about the status.
Even when developers are just experimenting with something, you can tell them that the tools they are looking into for future use have issues that need to be addressed before going into production. This may help them with their evaluation.
Bake security into your processes. Embed it in your teams.
Rabobanks' journey to agile and DevOps security — Alex Duivelshof (Rabobank)
Security needs to be part of the continuous delivery process as early as possible.
They identified a number of risks:
- Fraud
- Rapid delivery of features can also mean rapid delivery of mistakes
- Data exposure
- Unauthorized access
- Security debt in time (many small changes combined can become a big change)

One of the key principles in DevOps is shifting responsibility back to the teams. We can do the same for security related issues.
Security principles they identified:
- Maintain (code) integrity including audit trail of code changes.
- Enforce four eyes for every change to production.
- Automate security testing where possible.
- Reduce impact by release methodology.
- Prevent unauthorized access.
- All processes are auditable.
(These principles are not new by the way—they already existed.)
The security officers asked the teams how they would apply the principles.
Security principles were geared towards implementation. The teams noticed that there were no principles for the security of the product. The security officers are now translating their requirements to business features. This makes it easier for product owners to understand what is needed and why.
Working with the teams and being available and involved from the beginning requires a different state of mind for the security officers.