Devopsdays Amsterdam 2018: day two
Table of Contents
The second, and last, day of talks of devopsdays in Amsterdam this year.
Note: these are my notes. They are not necessarily representative summaries of the talks.

Monitoring the dynamic nature of cloud computing — Lee Atchison (New Relic)
It is the busiest day of the year for your company, can you scale en keep your application running and, with it, keep your customers happy?
Many of us don’t have enough visibility into our application to know what is going on. Availability issues can be subtle. If 1% of your transactions is slow, some of your customers will not be happy. But on average the application is still fast enough. So you won’t see the problem if you look from the outside in. You need more information from all components and not just averages.
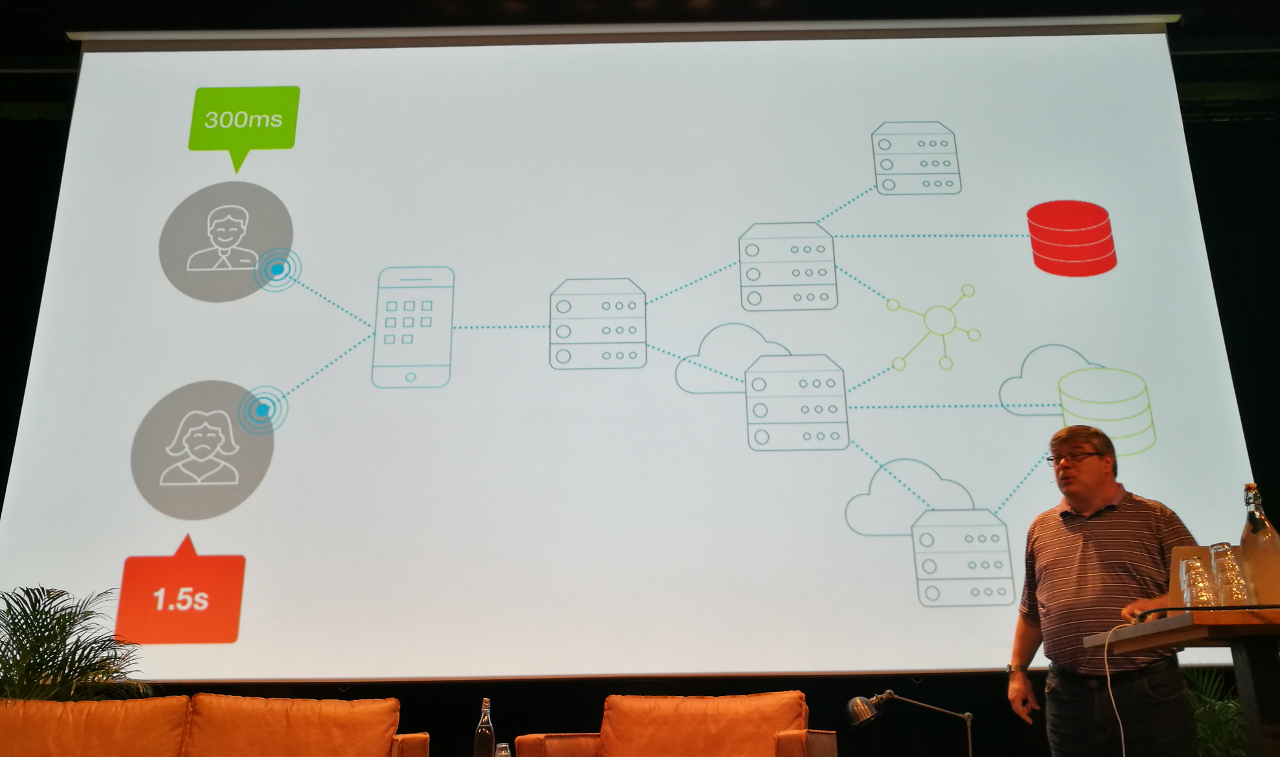
A properly monitored application generates lots of data. It might dwarf the actual business data.
What to collect metrics on:
- Business outcomes
- User experience
- Application
- Infrastructure
You need to know how your app is performing, what the customer experience is and what the business outcome is. The problem is that it is not just a static world with your own data centers anymore. In a modern world your applications and resources are more dynamic. The way you did things in the past, will not work in the future.
Long running containers do exist but are a minority. In a survey by New Relic (performed about three years ago) the average container life was about 200 days. But most containers (11% of all containers in the survey) lived less than one minute! Things you monitored 10 minutes ago, don’t exist anymore now.
So how do you track what the dynamic cloud is doing for (or to) you? The dynamic cloud has unique monitoring requirements.
A dynamic cloud application:
- Allocates resources on demand
- Resizes resources on demand
- Has an automated provisioning process
- Still has services to monitor
- Still has servers to monitor
- Still has infrastructure
- Still has user interfaces
You need to monitor the components themselves (how are the resources working) and the lifecycle of the components (which resources were used).
Monitoring dynamic applications means you have to monitor:
- What was running, and when
- Provisioning process
- Static usage
In the past, when the rate of change was low, you could get away with monitoring the server. A change meant a problem. Today, change is the normal operation.
More important than “picking the tool to use” is understanding what you have to monitor, what your application architecture is like, etc.
In most unexpected incidents (in properly instrumented systems) data was collected, and it helped investigating the issue afterwards. The issue was that people were not looking at the right data to avoid the incident. It is hard to collect too much data.
About retention times: two weeks, three months and one year are the most common retention times. But this differs per type of metric. For example, you might want to keep your business metrics for a year but other metrics only for two weeks.
Chaos while deploying AI and making sure it doesn’t hurt your app — Thiago de Faria (LINKIT)
Definitions Thiago uses:
- AI
- Make computers capable of doing things that, when done by a human, would be thought to require intelligence.
- ML
- Make machines find patterns without explicitly programming them to do so.
To properly use AI/ML you need a data scientist. This person probably does not have a connection with dev or ops and works in a different department. The scientist might collect data from a data warehouse, put it in a CSV and work on their laptop. They build a golden data set.
After a while, they have a model that is, say, 90% accurate. They show it to the CEO, which is happy with the data scientist. Then they go to the ops team and say “deploy this.” And “this” might be a Jupyter notebook. How do you deploy something like that?

Dev has to convert the model into something that can be deployed. Ops will have to figure out how to run and monitor it, etc. But these teams were not involved in the process of creating the model. And building that golden data set, that was used by the model, might take too long to generate real time.
You also have to tweak the model over time to keep the it accurate. The data scientist needs to be part of the team to maintain the model.
Data scientists have a different way of working. A couple of months of work sometimes results in only one or two commits. What the scientist tried and experimented with to get to these commits gets lost. This can lead to a lot of rework if another scientist continues to work on the model. (“Oh let’s try <idea that the original data scientist already tried here>.”)
ML and data science should be part of the building pipeline. This requires a culture change. Apply regular software engineering practices to data science.
Databricks recently released mlflow which you can use to track experiments: what have you tried, what worked and what not, which commit was it, etc.
That product team really brought that room together — Harold “Waldo” Grunenwald (Datadog)
DevOps is a concept, a philosophy. “DevOps” doesn’t do work, people do.
Writing code is not the end goal. The business needs an application that fulfils a business goal. If you treat development as a project and operations as a service, who cleans up the mess?
You need a product team: a self-contained, long lived team, which includes development, operations and maintenance. Not “everybody can do everything” but “everyone can figure out everything”.
Product leaders (product owners) own the product and decide on the team. You still need functional leaders for the company though. All work comes from the product owner. Functional leaders help with individual growth.

Team size: depends on the roles you need. Perhaps you do not have dedicated roles, but people that have affinity for certain tasks.
The team won’t be “done” as long as the application is still in use. You need to create updates, maintain it, etc. The team can take in new work though.
I was too busy listening which meant that I did not take enough notes. My advise it to watch the video of the talk.
Have your cake and eat it too — Karen Cohen (Wix)
This talk is about how to make huge changes in your systems. For example: breaking a monolith and breaking it up into microservices—this kind of scale.
At a certain moment (about 4 years ago), her team got their golden ticket and was allowed to take a few months to rebuild the product. However, during the rebuild phase the team lost contact with the business and the customers. They needed a better approach.

To tackle their problems, they first came with a vision:
- Define roles and responsibilities for their system
- Internal domain modelling
- Terminology
They also communicated their vision with managers but also clients.
They discovered “everyday decision making.”
Co-evolution: the tech evolves as result of new feature requests. The product changes as a result of tech changes.
You have succeeded if other people, outside of your team, suggests something that aligns with your vision.
Summary for making big changes:
- Have a vision
- Communication it to everyone
Why tooling (only) isn’t the answer — Arnold van Wijnbergen (Devoteam)
Problems with tools:
- Missing features
- Missing integrations
- Missing alignment
The organization has an important role in the toolchain strategy. Conway’s law comes into play here.
There are a lot of tool vendors. You have to pick tools to support both the business and product teams.
What is an integrated toolchain? Arnold uses the
DevOps toolchain definition from Wikipedia:
A toolchain is a set or combination of tools that aid in the delivery, development, and
management of applications throughout the software development lifecycle, as
coordinated by an organization that uses DevOps practices.

Points of attention when defining your tooling strategy:
- You cannot please everyone, apply the 80/20 rule.
- Provide an open eco system, use a modular approach.
- Make it easy to consume by providing an API.
- Evolve by learning and adoption.
- Offer support and education.
A fool with a tool is still a fool
Integrations are important to optimize the feedback loops. This generates a lot of data. Don’t waste it, but share and learn from it.
Some common pitfalls:
- Technology push from ivory tower, no input from key users.
- Tools that don’t match with what is needed and thus remain unused.
- Tools that are handled like a black box, that is without proper integrations.
- Closed ecosystems.
Your tooling strategy can be an accelerator for your whole enterprise. Talk to other teams and learn from them. Tooling is meant to unburden the product teams. Ideally the tools are self-supportable (for instance via documentation). Don’t forget to collect metrics to improve support and quality.