Open Source Summit Europe 2018: day two
Table of Contents
Another set of notes taken at the Open Source Summit Europe 2018.
These are just notes. They are not proper summaries of the talks.

Three years of Lessons from Running Potentially Malicious Code Inside Containers — Ben Hall (Katacoda)
Katacoda is an interactive learning environment where people can get shell access on machines provided by Katacoda via their browser. People are prone to experiment. Katacoda needs to make sure that one person cannot have an impact on other customers.
Docker has a number of security related features, like:
- Running as a non root user in the container.
- File isolation via copy on write.
- Limits on what resources users can use (memory, CPU), via cgroups.
- Constrict a container via namespaces.
- Restrict privileges so you cannot use e.g. setuid/setgid.
- Seccomp to limit system calls.
- Running profiles via AppArmor.
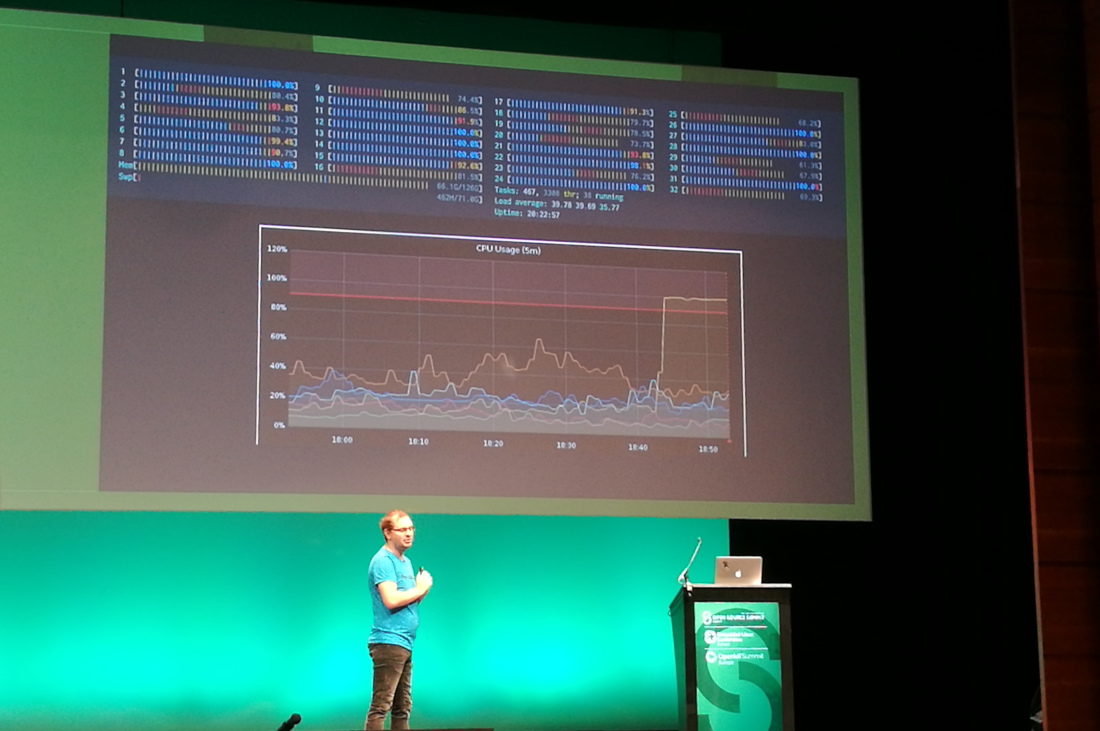
You need visibility into your containers. If the CPU spikes, is there cryptocurrency mining going on, or is it a legitimate machine learning job?
How do we solve a problem like mining? Cgroups are not enough. You would like to have traffic shaping to e.g. limit the amount of data a container can send. You can also:
- Kill long running processes (easier to do when using orchestrators like Docker Swarm or Kubernetes)
- Block or restrict outbound network traffic (block by default and only allow legit usage)
You could use iptables for the latter. However, this does not work with Docker since it uses a separate Docker chain. When running in Kubernetes it would be easier via a service mesh (like Consul or Istio).
But if you cannot block everything, it fundamentally is a cat and mouse game.
When the host is attacked via a container, having privileged containers is the worst since you can easily break out of them (inserting SSH keys, finding Docker credentials, etc, etc).
You can limit the number of processes to prevent e.g. fork bombs
(--pids-limit=2048).
Visibility into your system is key.
Tips:
- Log iptables drops
- Sysdig Falco
- Have a security pipeline (e.g. using Aqua)
Are containers secure? Fundamentally yes. But you also have to think about the security measures that are in place.
Quick wins:
- Don’t allow root
- Read only file systems
- Block egress (why do you need run
apt-getin production?) - Network policies / service mesh / Istio!
- Create visibility
Cloud Object Storage: The Right Way — Orit Wasserman (Lightbits Labs)
Objects are organized in a bucket (like a folder, but they cannot be nested) and are immutable. Cloud object storage means you use a restful API to access the objects. Common clouds: AWS S3, Swift (OpenStack), Google cloud storage and Ceph (which can be used as private cloud object storage solution).
You’ll want to use cloud object storage:
- if you need to scale
- have lots of large objects that are rarely updated
- have small objects that are infrequently updated and are not performance sensitive
- slow hard drives
When not to use cloud object storage:
- When the application does a lot of in place writes in big files.
- Legacy applications that cannot use the object storage API.
Special features:
- Multipart upload
- Upload one object as a set of parts (initiate object, upload the bits and complete the object).
- Benefits are improved throughput, quick recovery from network issues, pause/resume upload.
- Pitfalls: not recommended for small objects, limit for regular uploads is 5GB, unless you are careful you can leave orphans after incomplete uploads.
- Versioning
- Not enables by default because it takes up space (and you pay for what you use).
- Lifecycle
- Expire old objects.
- Move objects to colder storage.
- Virtual hierarchy
- By adding a prefix you can ‘fake’ hierarchy.
- Static website
- Cloud storage already has a webserver. You can serve your website directly from cloud object storage.

To increase security of your cloud object storage usage, you should use signatures if your provider and SDK support it.
You should also encrypt the traffic (there is a performance penalty though). Server side encryption is not enough because this means you will have to trust your cloud provider. You should also encrypt client side (SSE-C or SSE-KMS).
Pay attention to access control. It might not be simple or convenient, but please use it. Give as little permission as needed. Be very careful with public buckets!
Even though your storage is now safe, you can still have a disaster you need to recover from. You need to have a disaster recovery plan and test that plan regularly. Ceph provides geo replication.
Replication in Ceph makes a distinction between metadata and data operations. Metadata is usually small and updated infrequently. It is replicated synchronous.
Data on the other hand is usually about large amounts of data and there are frequent operations. These operations are asynchronous.
(Slides)
Cloud-init: The cross-cloud Magic Sauce — Scott Moser & Chad Smith (Canonical)
Cloud-init helps with initial initialization, which is convenient for you. It also allows cloud platform providers to have a few generic images and only on instantiation make them specific (instead of having thousands of specific images to begin with). Cloud-init supports a bunch of distributions, not just Ubuntu. It also supports many cloud providers.

The goals of cloud-init:
- Remove the need to make a custom image or reboot. There are a couple of moment where you can execute code: ASAP, once the network is up or at the end.
- Option to create an image from a snapshot. You can choose to execute code on boot once, per instance or per boot.
- Make it easier to migrate to different clouds.
- OSes should only have to ship one single image.
Instance input:
- Disk image
- Meta data (hostname, authorization info like SSH keys, etc)
- Network configuration (multiple NICs and IPs, bridges, vlans, etc)
- User data (e.g. commands to execute)
- Vendor data (like vendor data but for the platform)
Cloud-init wanted to provide a common interface since every cloud provider does things (slightly) different.
Cloud-init provides specific configuration to (amongst others):
- Grow the root partition
- Add/upgrade packages
- Set the timezone/locale
- Run arbitrary code
- Start Puppet or Chef
Notable changes in cloud-init versions 18.4 and 18.5:
- Standardized instance metadata in
/run/cloud-init/instance-data.json - Extended command line tooling (
query,analyzeandstatus). - Automatic network configuration based on metadata/udev events (to come in 18.5)
You can use Jinja templates for your cloud-init config. The example from the slides:
## template: jinja
#cloud-config
{% set HN='oss-' ~ v1.platform ~ '-' ~ v1.region ~ '-' ~ range(9) | random %}
puppet:
conf:
agent:
server: puppetserver.blackboxsw.com
certname: {{ HN }}
hostname: {{ HN }}
...
{% if v1.region == 'us-east-2' and v1.cloud_name == 'aws' -%}
echo 'Installing custom proxies ...’
{%- endif %}
(Slides)