All Day DevOps 2021
Table of Contents
All Day DevOps, the free online DevOps conference that goes on for 24 hours, was held for the 6th time today. With a total of 180 speakers spread over 6 tracks, there’s even more content than the last time I attended. These are the notes I took during the day.

Derek Weeks opening the day for All Day DevOps
Keynote: CAMS Then and Now and the Path Forward — Thomas “VikingOps” Krag
When people think about DevOps, they think of CAMS, which stands for:
- Culture
- Automation
- Measurement
- Sharing
The term CAMS was formalized by John Willis and he wrote down his idea in the article What Devops Means to Me. This talk will focus on the most important aspect: culture, and specifically organizational learning.
Culture
Culture as described by Simon Sinek:
A group of people with a common set of values and beliefs. When we’re surrounded by people who believe what we believe something remarkable happens. Trust emerges.
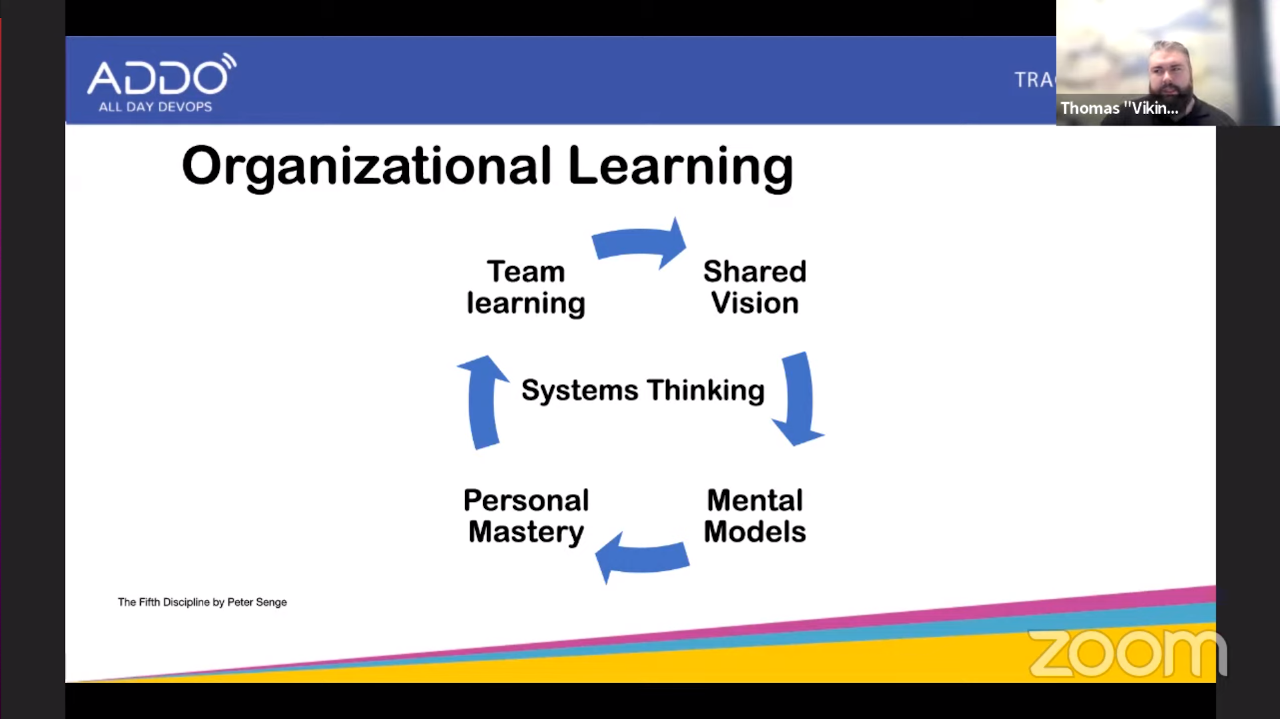
The 5 disciplines from organizational learning:
- Shared vision
- Have people play the game not just because of the rules, but because they feel responsible for the game.
- Mental Models
- Breaking your own assumptions and how they can influence your actions. You need to self-reflect on your own beliefs.
- Personal Mastery
- This is about owning yourself, learning and achieving your personal goals. And to do the latter you first need to define what is important for yourself.
- Team learning
- Effective teamwork leads to results that persons cannot achieve on their own. And individuals working as a team can learn faster than they would by themselves.
- Systems Thinking
- Looking into patterns that emerge inside your organization from a holistic viewpoint instead of just looking at your own team.
Automation
Automation is about automating the right things. You don’t want to do it just to automate things, but it has to fit in the system. So you have to start with culture before you think about automation. The ultimate goal is GitOps where everything happens via a pull request.
Measurement
Measurement started out with a focus on the tooling. But measuring how you work is as important as measuring your infrastructure.
Important key metrics, from DORA:
- deployment frequency (how often do you release to production)
- lead time for changes (the amount of time for a change to get into production)
- time to restore service (how long does it take to recover from a failure in production)
- change failure rate (the percentage of deployments causing a failure in production)
Sharing
Share how you are doing (in) DevOps. This is how we ended up here now. Share how you are improving your own organization. But also share information within your organization: documentation, videos, presentations, open spaces, lean coffee sessions
Three ways
CAMS originated in 2010. The three ways are principles that came out of the book The Phoenix Project. They are:
- 1st way: create flow (systems thinking)
- 2nd way: feedback loops
- 3nd way: experimentation, risks, learning
If we map these to CAMS:
- Culture: 3rd way
- Automation: 1st way
- Measurement: 2nd way
- Sharing: 3rd way
Working on your culture is as important as doing your actual work.
So what’s next? CAMS is still as applicable as 10 years ago. It has always been important, but it was only put into words in 2010. We need to continue sharing to get the full value out of it.
Gamification of Chaos Testing — Bram Vogelaar
We think of Usain Bolt as the record breaking athlete, but he’s also the person that worked really hard to get there. It takes a lot of time and effort to become good at something. Pilots and firemen spend most of their time training and not doing what you expect them to do; just to make sure they perform well under pressure. Also note that pilots use a lot of checklists to prevent mistakes.
We should do the same: train for when our platform is in an error state. We should not just be able to detect it, but also solve the problem.
Chaos engineering is the discipline of experimenting on a distributed system
in order to build confidence in the system’s capability to
withstand turbulent conditions in production.
This
practice started at Netflix with Chaos Monkey.
We need to become comfortable with experimenting. Have game day exercises and analyze what happened, to improve your training. Do not just focus on the result of the exercise itself, but also ask questions like “was it the right experiment?”
Now that we use containers, add sidecar containers with tools to get metrics or detect errors. Or to do chaos engineering e.g. with Toxiproxy.
Since checklists are boring, we can use gamification to spice things up. Celebrate failure, and learn from it!
Living in the year 3000: breaking production on purpose on Saturdays and have the system remedy the problem itself.
Convince management that failure is normal and expected behaviour. Promising 100% uptime is not realistic. Large, complex systems will always be in a (somewhat) degraded state.
Let engineers be scientists to deal with this complex environment. Give them training, allow them to do tests (experiments), which results in having valid monitoring that lead to actionable alerts. Get the engineers in a state where they are comfortable with failures.
(Slides)
Watch Your Wallet! Cost Optimizations in AWS — Renato Losio
Each AWS service has it’s own price components. It’s a complex subject. Even a simple service like a load balancer has multiple components. It looks simple with the “$0.008 per LCU-hour” price tag, but now you have to figure out what an LCU-hour is. Then you learn it has four dimensions that are measured: number of new connections per second, active connections, processed bytes and rule evaluations. Good luck predicting the costs.
This presentation only sticks to the basics since cost optimization it such a big topic.
To start to manage/reduce your costs, you need to enable billing and costs for your DevOps team. If you cannot measure your costs, you cannot manage it. Note that you do not need an excessive amount of tags for cost management. First you need to figure out what you are going to change and how it’s going to affect the bill for your company.
When savings can be measured, they can be recognized, and cost efficiency projects become exciting opportunities. As of early 2021, the most viewed dashboard at Airbnb is a dashboard of AWS costs.
What patterns can we avoid? In most organizations, the most expensive parts of your bill will be:
- Compute
- Storage
- Data transfer
So we will dive into these subjects.
Compute
Tips to reduce costs:
- Avoid fixed IP addresses where possible. This is not so much about the costs of the IP address itself, but mostly because architectures that require a fixed IP tend to be complex and more expensive.
- Use Graviton (ARM) instances. They have a better price to performance ratio. You can also migrate managed services (RDS, Lambda functions) to Graviton.
- Check out Lightsail. It’s less flexible than using EC2 instances, but cheaper.
Data transfer
We usually forget to take data transfer costs into account upfront. It’s also a complex subject and there are a lot of considerations to make.
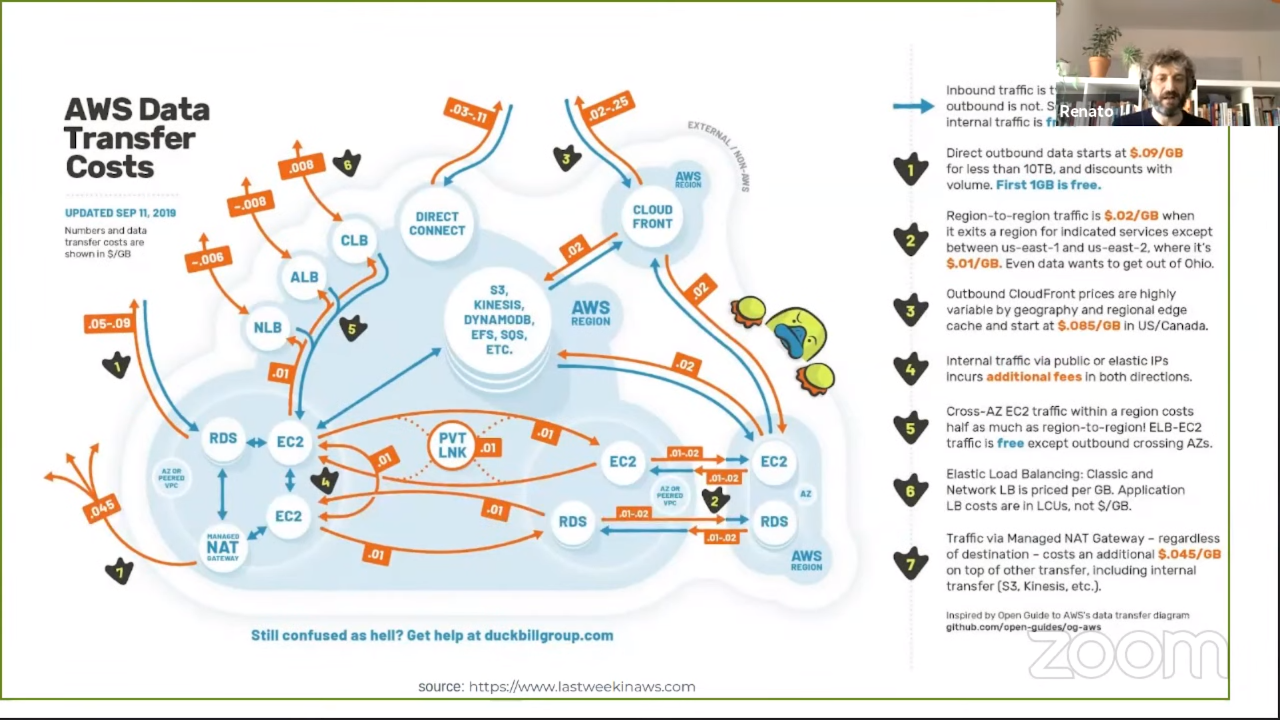
Tips:
- Multi AZ is always good, but are 3 zones always better than 2 zones?
- Multi region is easy to do nowadays, but expensive with regard to data transfer. Ask yourself if you really need it.
- If you want to use multiple cloud providers always think about the data transfer costs. Perhaps the storage costs are lower at provider X, but if you have to transfer data, you’ll probably pay an egress cost.
- Using a CDN (CloudFront) might be cheaper than paying for the egress data transfer otherwise.
Storage
Initially it was simple: there were only two storage classes. Currently there are 6 different classes with their own prices and characteristics.
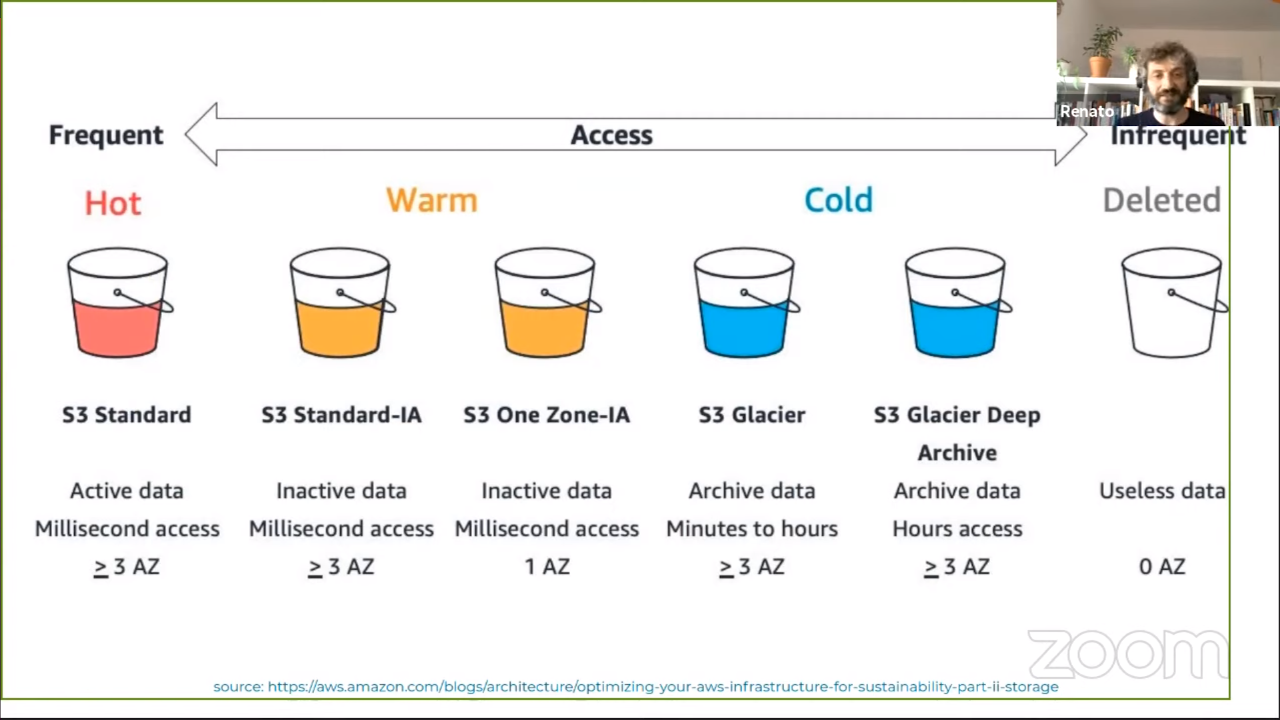
The best option is to use lifecycle rules to move data between different
classes. Note that you in a lifecycle policy you cannot filter the objects based
on an extension (e.g. *.jpg) but instead you need to think “from left to
right.” So you need to think upfront about the prefixes you are going to want to
use in your bucket.
Managed services can offer you automatic and manual backups, which can be great. But what is the cost of that? Check how much retention you need for example.
With regard to EBS: for most use cases gp3 is better and cheaper than gp2
(except for very large volumes). Note that you can change the EBS volume type
without stopping the machine. In most cases you can have a 20% cost saving
without affecting your performance.
AWS changes quickly
After each AWS re:Invent, your deployment is probably outdated with regard to cost optimizations. Examples:
- Use
gp3instead ofgp2for your EBS volumes. - The instance type
m6might be more interesting than them5orm4you may currently be using. - Dublin was the cheapest region in Europe, but for most things Stockholm is cheaper than Dublin at the moment.
So keep up to date with the offerings.
Keynote: Call for Code with The Linux Foundation: Contributing to Tech-for-Good Even if You’re Not Techincal — Daniel Krook and Demi Ajayi
Call for Code is a multi year program launched in 2018 to address humanitarian issues and help bridge potential solutions. Last year the global challenge was around climate change and a track was added for the social and business impact of the COVID-19 pandemic.
It’s not just about generating ideas to take on the issues. It should eventually also lead to an adopted open source solution that is sustainable.
The 14 projects discussed today can be found on Call for Code page on the Linux Foundation website. You can also read about them via the IBM developer site. GitHub is central for how they iterate on the features. The related organizations are :
The key takeaway for this session is to make us help improve how the projects do DevOps. The goal is to ensure that everyone can contribute to the projects, can do so with confidence and the projects can be deployed with speed.
The Call for Code for Racial Justice open source projects are categorised in three pillars:
- Police reform and judicial accountability:
- Diverse representation:
- Policy and legislative reform:
Demi talked about each of these projects in the program and their tech stacks. You can read more about them on the Call for Code for Radical Justice section on the IBM developer site.
Daniel in turn talked about other Call for Code projects:
Even if you cannot code, there are numerous ways you can contribute, e.g. conducting user research, write/review documentation, do design work, advocacy like speaking at conferences.

There are multiple ways to get involved:
- Via the virtual community (join slack, join events)
- Directly via the projects on GitHub
- Conduct outreach (recruit friends, host events, etc)
DevSecOps Culture: Laughing Through the Failures — Chris Romeo
Chris shared 10 DevSecOps failures and talked about how to change the culture and turn these failures into successes.
#1 Name and brand
This quote nicely sums it up:
Can we stop the {Sec}Dev{Sec}Ops{Sec} naming foolishness?
Just call it DevOps and focus on making security a natural part of building stuff.
To change the culture:
- Embrace security and make it part of DevOps
- Teach this new definition to everyone involved with your project (developers, testers, product managers, executives, etc)
- Create a “DevSecOps” swear jar ;-)
#2 The infinity graph
The problem is that nothing ever gets done with this infinity graph. It’s not an accurate representation.
The solution is to talk about pipelines instead and integrating security into them. Code review should include security, vulnerability scanning should be part of the pipeline, etc. Ban the infinity graph.
#3 Security as a special team
Creating a specific security team is the opposite of what DevOps is about. It’s about working together. Security isn’t a specialty, it is the responsibility of everybody. This requires knowledge and expertise.
The other way around is also true: teach security people to code. They don’t have to become great coders, but it would be nice if they can review code and make suggestions to make things more secure.
#4 Vendor defined DevOps
Sometimes we let vendors define what DevOps and security are for us, via the products that they offer. It would be better to find the best of breed outside of the offering of cloud provider. Take a vendor independent approach and determine what DevOps means to you.
#5 Big company envy
Looking at the big companies can be discouraging. You most likely have not invested the same time in it as e.g. Netflix, Etsy, etc. have. So while you won’t be at the same level, don’t see this as an excuse to give up. Do the DevOps that you do. Don’t fixate on the top of the class. Get on that path and make incremental progress.
Use the OWASP DevSecOps Maturity Model to create a roadmap.
#6 Overcomplicated pipelines and doing everything now
This can be a complicated subject (see for example the DevSecOps Reference Architecture from Sonatype).
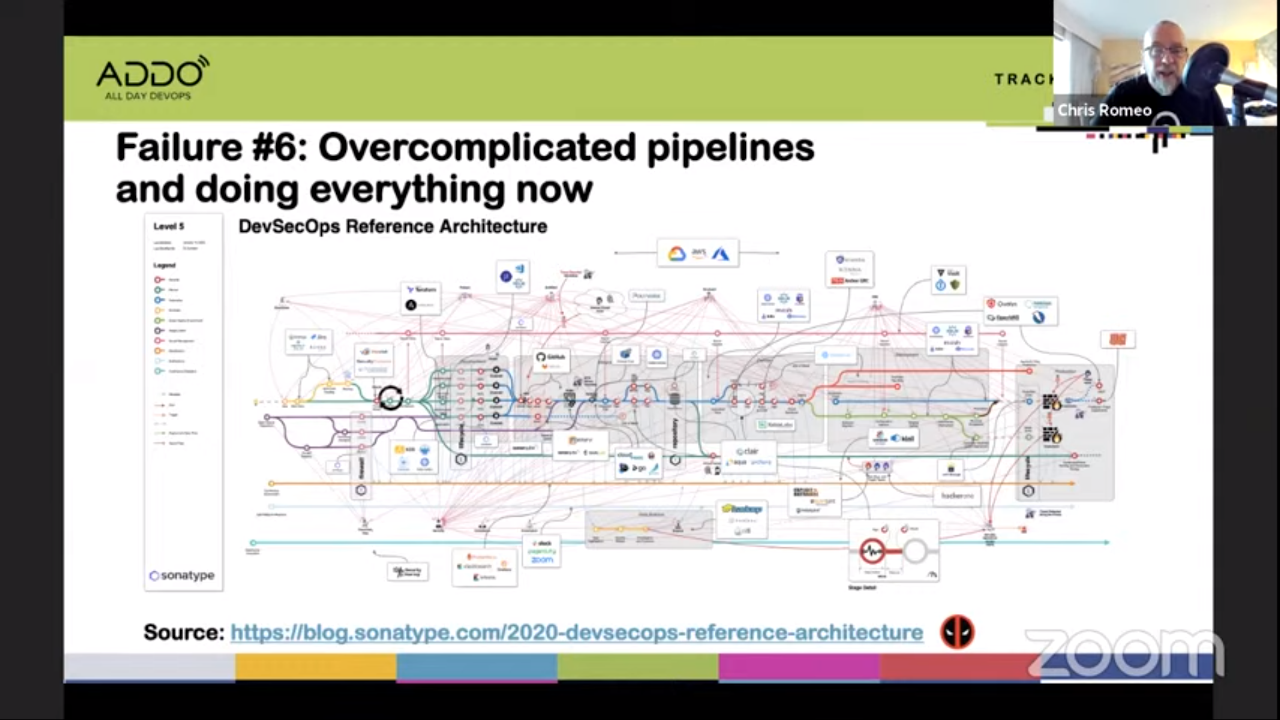
But keep it simple! Start with a small subset of security tools. Everybody related to your project should be able to explain the build pipeline. Don’t try to solve all problems immediately. Take a phased approach.
#7 Security as gatekeeper
Security might want to slow down the pipeline and act as a gatekeeper. Don’t say “no,” but “yes, if…” For example: “yes, that would be a great feature if you enable multifactor authentication.”
Practice empathy. Both security people for developers, but also the other way around.
#8 Noisy security tools
You buy a tool and enable every option to “get your money’s worth.” The result is 10,000 JIRA tickets of things that need to be fixed. This does not help.
It would be better to tune the tools and don’t waste time with security findings that do not matter.
Start with a minimal policy focussing on the largest issue. Developers will then start to trust the tool and then you can slowly increase the policy.
#9 Lack of threat modelling
You scanning tools cannot find business logic flaws; there’s no pattern to it.

Perform threat modelling outside of the pipeline. It should be done when new feature assignments go out.
#10 Vulnerable code in the wild
There are lots of vulnerabilities in open source software; this is a supply chain problem.
To improve this: embed software composition analysis (SCA) in all your pipelines. Set the SCA policy to fail when a vulnerability is detected. If you filter out a vulnerability (e.g. because there’s no fix yet), make sure the filter will not be active forever.
Successes
The 10 DevOps successes we can distil from the failures above:
- Just call it DevOps
- Pipelines
- Security for everyone
- Embrace your DevOps
- Be content with your DevOps
- Simple and staged pipeline
- Security as trusted partner
- Tuned and valuable security tools
- Threat modelling for everyone
- Breaking the build for vulnerabilities
Key takeaways
- Hopefully the real impact of DevOps (when looking back 50 years from now) is going to be security culture related.
- Some of the failures were outside of your control, but you can change them.
- Everybody has to code, choose your DevOps, keep it simple, lower the noise, add the best practices we discussed, do some threat modelling, break the build for vulnerabilities.
- Embrace and laugh at the failures.
Keynote: Managing Risk with Service Level Objectives and Chaos Engineering — Liz Fong-Jones
Besides being a principal developer advocate at Honeycomb, Liz is also a member of the platform on-call rotation. Honeycomb deploys with confidence up to 14 times a day, every day of the week—so also on Fridays. How do they manage to (mostly) meet their Service Level Objectives (SLOs) while also scaling out their user traffic?
Their confidence recipe:
- Quantify the amount of reliability.
- Be able to identify risk areas that might prevent them from fulfilling their targets.
- Test to verify that the assumptions about the systems are correct.
- Respond to that feedback to address the problems found via those experiments or though natural outages.
How to measure reliability?
You need to know how broken is “too broken.” You don’t have to alert on all problems when working at scale. You need to measure success of the service and define SLOs. These are a way to measure and quantify your reliability.
Honeycomb’s jobs is to reliably ingest telemetry, index it, store it safely and let people query it in near-real-time. Honeycomb’s SLOs measure the things that their customers care about.
For example, they have set an SLO that the homepage needs to load quickly (within a few hundred milliseconds) in 99.9% of the times. User queries need to be run successful “only” 99% of the time and are allowed to take up to 10 seconds. On the other hand: ingestion needs to succeed in 99.99% of the time since they only have one shot at it.
Services are not just 100% down or 100% up (most of the time).
These metrics help Honeycomb make decisions about reliability and product velocity. If the service is down too much, they need to invest in reliability (since having features that cannot be used does not add value). On the other hand: if they exceed the SLO, they can move faster.
Recipe for shipping reliably and quickly
Practices used by Honeycomb:
- Code is instrumented. Think beforehand what a success or failure in production would look like.
- Functional and visual testing using libraries that create snapshots.
- The design for feature flag deployment (only making a feature available to a small percentage of users initially).
- Practice automated integration plus human review. (There’s an SLO for how long the tests are allowed to take. Code reviews are high priority tasks since you are blocking someone else by not reviewing their code.)
- The main branch is safe to release any time.
- Automatically roll out the changes.
- After the deployment the engineers have to observe what is happening with their code in production. Only after they confirm that everything is okay, they can go home. So you are free to deploy on Friday at 19:30 as long as you are willing to stick around until your code is deployed and you have confirmed it is not causing issues.
For infrastructure Honeycomb also use infrastructure as code practices:
- They can use CI and feature flags for their infrastructure.
- They can automatically provision fleets if needed.
- They can automatically quarantine certain paths to keep the main fleet from crashing or do performance profiling.
Chaos Engineering
Left-over error budget is used for chaos engineering experiments. This is something where you go test a hypothesis. You need to control the percentage of users affected by it and be able to revert the impact you are causing.
Chaos engineering is engineering. It’s not pure chaos.
This works well for stateless things, but how does it work for stateful things? In the case of the Honeycomb infrastructure, they make sure to only restart one server or service at a time. They do not introduce too much chaos to reduce the likelihood that something goes catastrophically wrong.
Two reasons why you will want to do these experiments at 3 PM and not at 3 AM:
- You want to test at peak traffic instead of low traffic, since the latter could give you a false sense of security in situations when everything may still look normal even though this would have been a problem in a high traffic situation.
- When doing things in the afternoon, there are more people available to deal with something than there would be in the middle of the night.
With the experiments they measure if they had an impact on the customer experience. If they cause a change, does the telemetry reflect this? (Is the node indeed reported as being offline, for example?) When you fix things, you need to repeat the experiment and make sure the change indeed fixed the issue.

When you burn the error budget, the SRE book states that you should freeze deploys. Liz disagrees. If you freeze deploys, but continue with feature development, the risk of the next deployment only increases. Instead, Liz advocates for using the team’s time to work on reliability (i.e. change the nature of the work instead of stopping work).
Fast and reliable: pick both!
You don’t have to pick between fast and reliable. In a lot of ways fast is reliable. If you exercise your delivery pipelines every hour of every day, stopping becomes the anomaly instead of deploying.
Takeaways
- By designing the delivery pipeline for reliability, Honeycomb can meet their SLOs.
- Feature flag can reduce blast radius, and keep you within your SLO.
- And when they cannot: there are other ways to mitigate the risks.
- By discovering risks at 3 PM and not 3 AM, you improve the customer experience since the system is more resilient.
- If something does go catastrophically wrong, remember that the SLO is a guideline not a rule. SLOs are for managing predictable-ish unknown-unknowns and not things that are completely outside of your control.
- We are all part of sociotechnical systems. Customers, engineers and stakeholders alike.
- Outages or failed experiments are learning opportunities, not reasons to fire someone.
- SLOs are an opportunity to have discussions about trade-offs between stability and speed.
- DevOps is about talking to each other and talking to our customers.
Common Pitfalls of Infrastructure as Code (And how to avoid them!) — Tim Davis
We start with the basics: what is Infrastructure as Code (IaC)? With the advent of cloud providers, you no longer use hardware, but a UI to stand up infrastructure. This led to shadow IT since developers ran off with a credit card to provision what they needed themselves, instead of using slow, internal IT systems.
Developers however rather write code and use developer methodologies than click through a UI. This is where IaC started. With it you can create and manage infrastructure by writing code.

What are he pitfalls? The bad news: you get all the pitfalls of infrastructure and all the pitfalls of code. But you’ve probably already got a lot of experience with those issues and teams to handle them. You just use a different methodology.
The first pitfall is not fostering the communication between the groups that have experience and tools.
Infrastructure pitfalls
Which framework/tool do you pick? There are basically two categories: multi-cloud or cloud agnostic tools on the one hand (like Terraform and Pulumi) and cloud specific tools on the other (like CloudFormation). Note that for example with Terraform and Pulumi you still have to rewrite code when switching from one cloud provider to another, but at least the tool is familiar.
Security is a huge thing. You still need to know how to design your VPC, IAM policies, security policies, etc. You still need to communicate with all the teams that have the experience. It’s not just Dev and Ops. With tools like Terrascan and Checkov you can shift-left the security aspect instead of trying to bolt it on afterwards.
Code pitfalls
The biggest thing issue is with default values. If you use the UI, there are a lot of boxes that may be blank or have stuff in them. Some of the boxes can be left blank, for some you need to specify what you want. The UI is going to yell at you; if you use IaC things may be less in your face.
You don’t want to deploy something with an open policy. Open Policy Agent can really help you to make sure you stay within your allowed parameters. For instance you can write a policy to make sure you are only use a specific region, don’t deploy an open S3 bucket or that you only use certain sizes of EC2 instances.
If you hard code certain values in Terraform or other IaC tools, you might need to copy/paste a lot of code if you want to create e.g. a test, acceptance and production environment. To mitigate these DRY (don’t repeat yourself) issues you can for instance use Terraform modules or Terragrunt.
State size can become a problem. If you want to, you can put all of your infrastructure in the same state file (which is where your tool stores the state of the infrastructure). However it means the tool will have to check all resources in the state file to detect if it needs to do something. To mitigate this, you can again use Terraform modules. It helps with performance and makes the codebase more manageable.
Wrap-up
The conference is still ongoing while I publish this post. However, this is it for me for All Day DevOps for this year. I learned new things and got inspired.
Thanks to the organizers, moderators and speakers for hosting another great event.